Deep Q-Learning for Atari Games
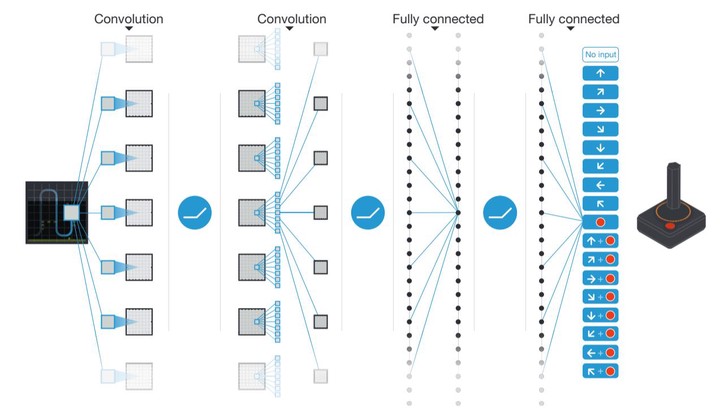 Image from DeepMind's paper
Image from DeepMind's paper
Introduction
The reinforcement learning has been around for more than a decade [2] , and Q-learning is one of most famous method for RL. DeepMind has especially utilized Q-learning, and evolved the idea to the next level by adapting non-linear model. Instead of Q table, Neural network is now used to predict the values, which is called Deep Q Network. The CNN and Deep Q-learning is what DeepMind’s work is all about.
Problem
DQN has to observe a game from ATARI and be trained to beat human level performance. Since Space Invader was the main example of early Deep-Mind’s paper, we are going to chose the game for this project. We are going to train our model to achieve the score of 500, which is the result of “Playing atari with deep reinforcement learn- ing.", the first DeepMind’s paper. And Space Invader is a game that human level performance is hard to achieve in the early works of DQN.
Related Work
DeepMind’s two early papers has two versions; we chose the version that uses three convolutional layers and one FC layer with 512 hidden units. This particular model for Space Invader has 6 outputs. All of the layers are followed by ReLU except the last output layer.
Target Network
Because of the shifting weights of Q model, DeepMind has suggested to use two Q networks. This is related to divergence of Reinforcement Learning. The first network consistently updates as normal DNN would, but the second network, called the target network, doesn’t have sequential updates but is used to estimate the value of next state. Because of this it’s updated every 10,000 frames, but this can be changed through hyperparameter settings. According to the Deep-Mind’s paper, target network prevents of falling into a bad local minima and shifting weights. Thus, the target network has different set of parameters θ.
Experience Replay
Our problem includes correlations of sequences of input which consists of actions and states. In order to break this, DeepMind suggests to use Experience Replay. Experience Replay is another word for big sampling pool. The continuous sequences of data can be recorded to become a large pool, which can be used for sampling later. As we get more and more data, having correlation between sampled batch is more unlikely. Thereby, sampled batchs can be treated as if they are independent themselves.
DQL Agent playing Space Invaders
Acknowledgement
- This project was advised by Prof. Justin Sirignano.
- This project was tested and reviewed by Seongsu Ha
Byung Il Choi
My research interests include Deep Learning, Information Retreival, and Computer Graphics.